
Revisiting Consistent Hashing with Bounded Loads
Load balancing is a fundamental task in most web services. For example, when a user clicks on a website, this requires locating a particular server, or cache, and then fetching the content. If the distribution of content is poor, e.g. in a video streaming service many popular videos are stored on the same server, this can lead to increased latency as users all try to fetch the content from the same server and, in the worst case, the server can crash. In another example, in order to retrieve an item from a database, it needs to be efficiently and conveniently stored to minimize both space and time requirements. In both cases, the challenge lies in efficiently storing and retrieving items in a distributed setting.
This year, our novel algorithm, Random Jump Consistent Hashing (RJCH), was accepted to AAAI 2021. Inspired by techniques in fast similarity search, we proposed an algorithm that can distribute load both evenly and without cycles. This led to improvements both theoretically and empirically.
Background
Two decades ago, a group of researchers proposed Consistent Hashing, a load balancing scheme which led to the multi-billion dollar company Akamai Technologies. Since then, variants have been applied across a range of household names for load balancing, including the 250 million+ chatapp Discord, AWS DynamoDB, Apache Cassandra, Google Cloud, Vimeo’s video streaming service and so on.
To understand the problem, consider the following simplified view. There are a total of n servers and each server contains some items which users request. For good load balancing, the items would be distributed evenly. However, there can’t be a centralized server to keep track of the load, otherwise it would get overloaded with user requests. As a result, a simple scheme to distribute the items satisfying the requirements is to assign item i into server hash(i) mod n. A problem arises when n changes: such a scheme would require the reassignment of most items.
In comes Consistent Hashing. Consistent Hashing treats the servers as residing on a unit circle, usually implemented as the locations hash(s) for server s on a large array. In this scheme, items are assigned to the closest server to hash(i). This way, when the number of servers changes, only a small number of items are reassigned.
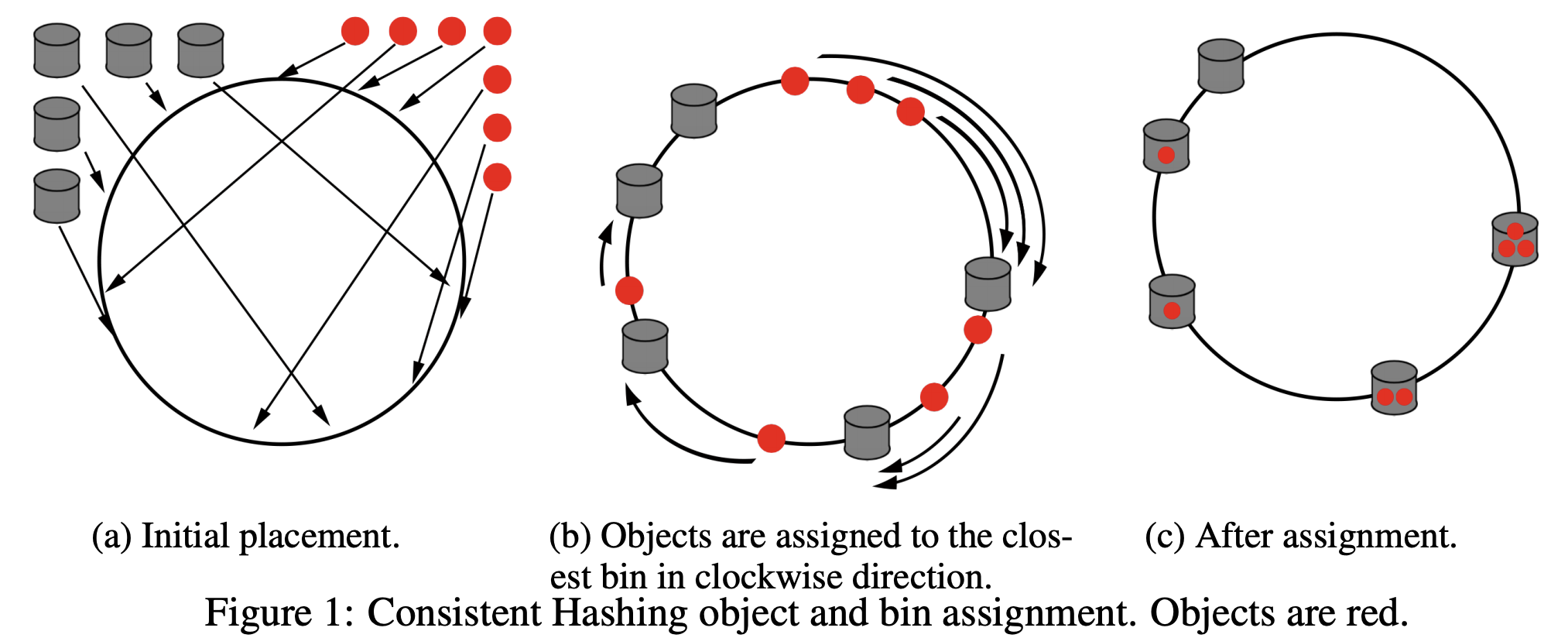
In 2016, a group of researchers from Google proposed an elegant extension termed Consistent Hashing with Bounded Loads. They observed that servers don’t have infinite capacity, and Consistent Hashing does not address this issue. They proposed to assign an item to the next closest server if the closest server was full. Implementations of Consistent Hashing with Bounded Loads (CH-BL) have yielded significant improvements in Google Cloud and Vimeo (see their great blog post here).
The Problem of Cascading Overflows
The issue with existing variants of Consistent Hashing lies with the cascaded overflow effect leading to poor load balancing. Once a particular server is full, the next closest server is more likely to fill up, and this can lead a significant number of consecutive full servers. Full servers bear a large load and have increased latency, and in the worst case can lead a series of cascaded failures of the servers in sequence.
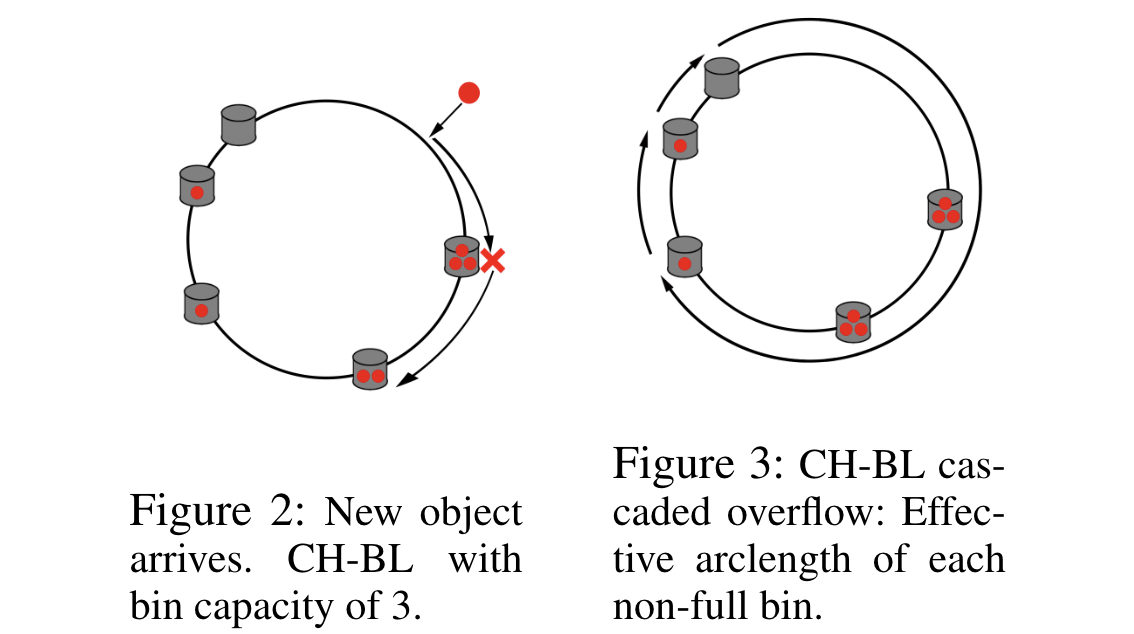
Our Proposal: Breaking the Cascade with Cycle Free Random Jump
In our proposal, we take a practical view of the state of distributed caching. We observe that items are typically cached after first being requested, as opposed to preemptively moved when servers are added or removed, and that there are some implementations which employ eviction schemes. We also observe that there is still room for improvement due to the cascading overflow effect, where if one server is full the next server will fill up faster leading to cascading overflow.
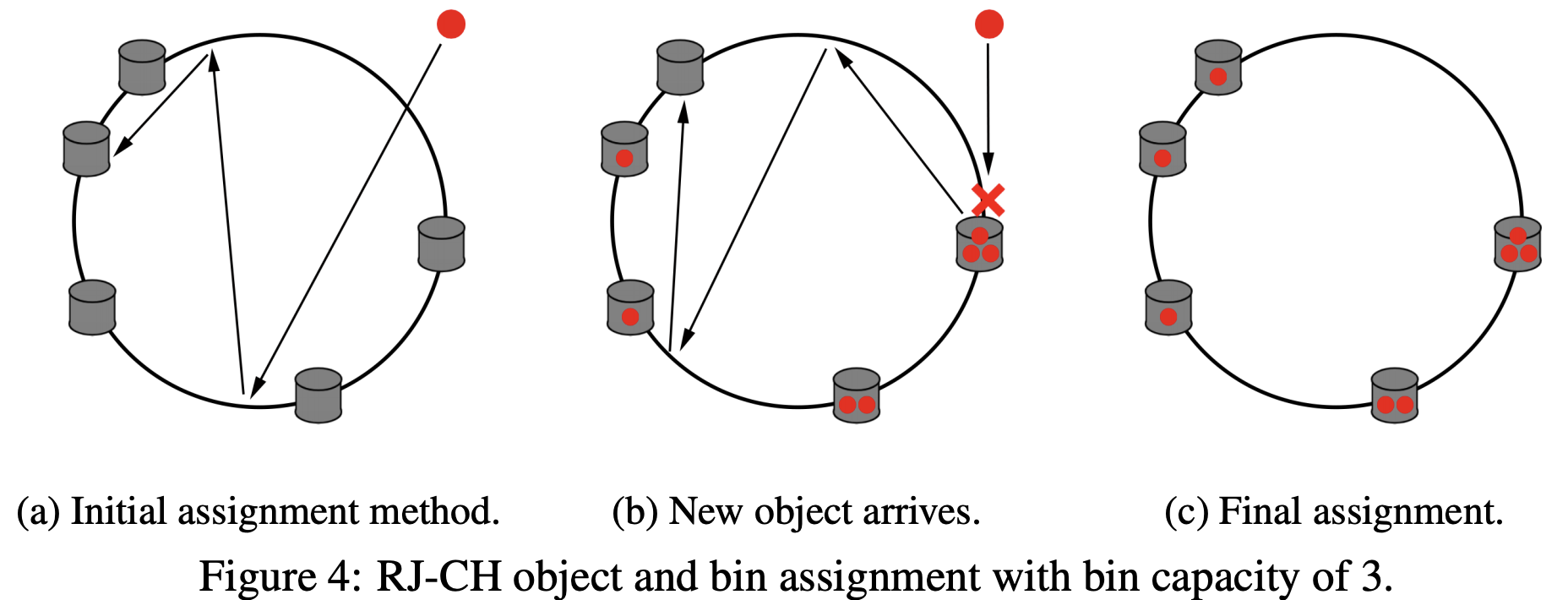
A naive solution is to repeatedly rehash an item i with hash(i), then hash(hash(i)), then hash(hash(hash(i))) and so forth, assigning the item to the first server it encounters. However, this leads to two issues: a) This is no better than the existing solutions since once two items end up with the same hash code any further hashing results in the same hash codes. This leads to cascading overflow. b) If a hash code is repeated, then this ends up in an infinite cycle.
In Random Jump Consistent Hashing (RJCH), we continuously rehash an item i with hash(i + j), where j counts the number of rehashes, and assign item i to server s if the hashes collide. The use of j seems innocuous, but is a simple and clever way to prevent cycles. The scheme is also still fast due to the blazing speed of murmurhash. Furthermore, the distribution of the load is extremely even, and in combination with the above practical view offsets any need or issues with reassignment.
Results
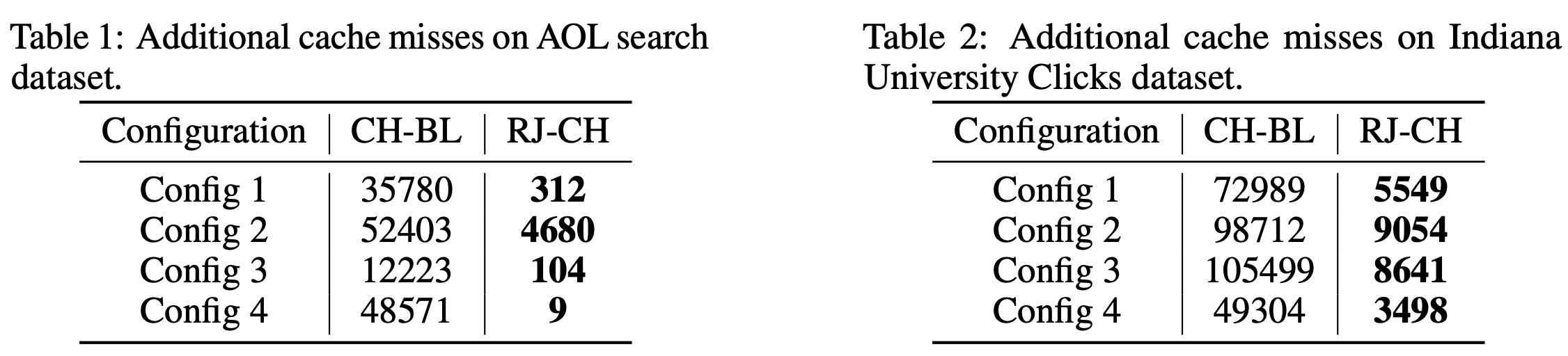
We applied RJCH and CH-BL to two distributed caching tasks under a variety of realistic configurations. RJCH reduces cache misses by up to several magnitudes on two real search log datasets.
We have many more settings in our paper - if you are interested in digging deeper, our paper is on arXiv! Thanks for reading.